Klasifikasi Logistic Regression Menggunakan Python & (Iris Dataset)

Dalam Machine Learning, klasifikasi adalah salah satu teknik yang penting dan paling sering digunakan. Pada artikel ini kita akan berfokus pada teknik klasifikasi sederhana terhadap spesies dari dataset Iris menggunakan Logistic Regression.
Logistic Regression merupakan sebuah model yang digunakan untuk melakukan prediksi apakah sesuatu bernilai benar atau salah (0 atau 1). Apabila pada linear regression garis yang terbentuk adalah garis lurus, tetapi pada logistic regression garis yang dibentuk mirip dengan huruf “S” antara titik 0 sampai 1.

Seperti pada gambar di atas dapat dilihat bahwa garis yang dibentuk oleh logistic regression memberitahu kita suatu peluang dari sesuatu dengan presentasi 0 (tidak terjadi/tidak tepat) — 0.5 (titik antara) dan 1 (terjadi/tepat).
Bagaimana algoritma tersebut bekerja? Logistic regression akan mengukur hubungan antara variabel target (yang ingin diprediksi) dan variabel input (fitur yang digunakan) dengan fungsi logistik. Probabilitas akan dihitung menggunakan fungsi sigmoid untuk mengubah nilai-nilai tadi menjadi 0 atau 1. Berikut gambar yang menjelaskan bagaimana proses ini terjadi.

Setelah mengetahui secara garis besar mengenai bagaimana logistic regression bekerja, kita akan langsung mulai ke tahap pemrogramannya. Pertama kalian harus mendownload dataset yang akan kita pakai yaitu Iris Species. Di sini kita akan melakukan prediksi terhadap spesies tumbuhan Iris berdasarkan karakterisik dari tumbuhan tersebut yaitu (Sepal Length, Sepal Width, Petal Length, Petal Width).
Let’s Code!
Di sini saya menggunakan Jupyter Notebook sebagai text editor untuk menjalankan program. Hal pertama yang harus dilakukan yaitu import semua library yang akan dipakai.

Setelah itu kita akan melakukan load data menggunakan pandas dan mencoba menampilkan sampel data.

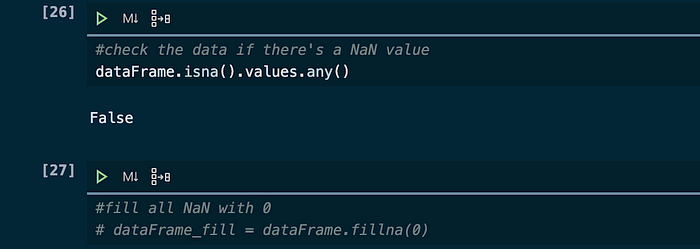
Jika data sudah di load, selanjutnya lakukan pengecekan apakah ada data yang tidak memiliki nilai atau NaN. Lakukan pengisian terhadap nilai kosong dengan variabel 0. Tetapi pada data ini tertulis false yang berarti semua data memiliki nilai sehingga dapat langsung diproses.
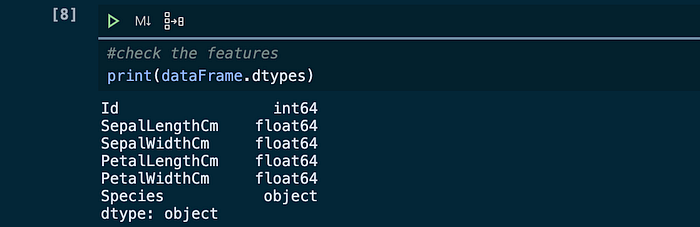
Untuk mempermudah meihat fitur-fitur yang terdapat pada dataset, kita dapat menggunakan fungsi dtypes.
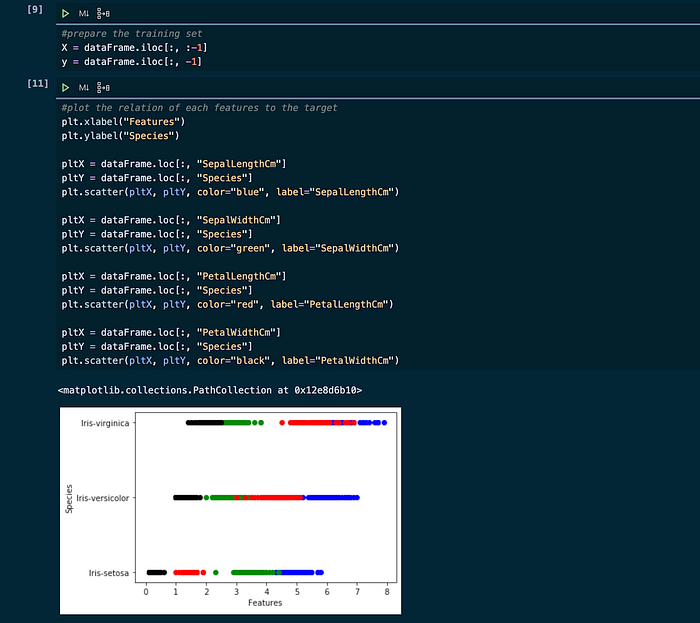
Pilih fitur yang akan digunakan sebagai input dan target prediksi. Lalu melakukan plotting untuk melihat realasi antar fitur.
# X = memilih semua fitur kecuali kolom terakhir
X = dataFrame.iloc[:, :-1]# y = memilih target yaitu kolom terakhir
y = dataFrame.iloc[:, -1]
Tahapan selanjutnya adalah melakukan pemisahan data untuk training dan testing. Mengapa ini penting? Hal ini diperlukan agar kita bisa melihat bagaimana algoritma belajar untuk melakukan prediksi pada testing data. Kita akan membagi data menjadi 80% training dan 20% testing menggunakan fungsi train_test_split() dari sklearn.model_selection.

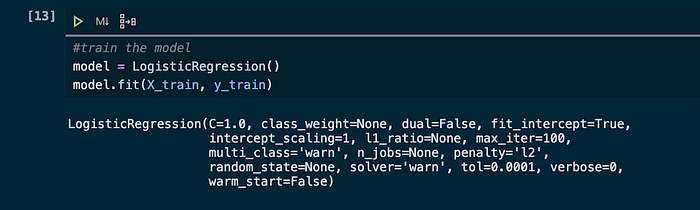
Setelah melakukan pemisahan data untuk training dan testing, langkah berikutnya yaitu melakukan train pada data yang ada menggunakan algoritma logistic regression. Berikut cara membuat dan melatih logistic regression model.
Sekarang setelah model dilatih, kita akan melakukan prediksi untuk melihat bagaimana performa model logistic regression terhadap testing data. Untuk mempermudah dalam melihay performa model, kita akan menggunakan beberapa metrics seperti precision, recall, f1-score.

That's it! Kita sudah berhasil melakukan klasifikasi sederhana menggunakan logistic regression terhadap spesies tumbuhan Iris. Seluruh code yang ditulis di atas dapat diakses pada akun Github saya.
Demikian artikel “Klasifikasi Logistic Regression Menggunakan Python & (Iris Dataset)”. Semoga dapat membantu kalian yang sedang mempelajari machine learning! Tetap semangat untuk belajar.
Stay save everyone! :)
